GPT-4 surprised many people with its abilities at coding, creative brainstorming, letter-writing, and other skills. Surprises in machine learning are not restricted to GPT-4: I was previously surprised by Minerva’s mathematical abilities, as were many competitive forecasters.
How can we be less surprised by developments in machine learning? Our brains often implicitly make a zeroth-order forecast: looking at the current state of the art, and adding on improvements that “feel reasonable”. But what “seems reasonable” is prone to cognitive bias, and will underestimate progress in a fast-moving field like ML. A more effective approach is first-order forecasting: quantifying the historical rate of progress and extrapolating it forward, while also considering reasons for possible slowdowns or speedups.[1]
In this post, I’ll use this approach to forecast the properties of large pretrained ML systems in 2030. I’ll refer throughout to “GPT2030”, a hypothetical system that has the capabilities, computational resources, and inference speed that we’d project for large language models in 2030 (but which was likely trained on other modalities as well, such as images). To forecast GPT2030’s properties, I consulted a variety of sources, including empirical scaling laws, projections of future compute and data availability, velocity of improvement on specific benchmarks, empirical inference speed of current systems, and possible future improvements in parallelism.
GPT2030’s capabilities turn out to be surprising (to me at least). In particular, GPT2030 will enjoy a number of significant advantages over current systems[2], as well as (in at least some important respects) current human workers:
- GPT2030 will likely be superhuman at various specific tasks, including coding, hacking, and math, and potentially protein design (Section 1).
- GPT2030 can “work” and “think” quickly: I estimate it will be 5x as fast as humans as measured by words processed per minute [range: 0.5x-20x][3], and that this could be increased to 125x by paying 5x more per FLOP (Section 2).
- GPT2030 can be copied arbitrarily and run in parallel. The organization that trains GPT2030 would have enough compute to run many parallel copies: I estimate enough to perform 1.8 million years of work when adjusted to human working speeds [range: 0.4M-10M years] (Section 3). Given the 5x speed-up in the previous point, this work could be done in 2.4 months.
- GPT2030's copies can share knowledge due to having identical model weights, allowing for rapid parallel learning: I estimate 2,500 human-equivalent years of learning in 1 day (Section 4).
- GPT2030 will be trained on additional modalities beyond text and images, possibly including counterintuitive modalities such as molecular structures, network traffic, low-level machine code, astronomical images, and brain scans. It may therefore possess a strong intuitive grasp of domains where we have limited experience, including forming concepts that we do not have (Section 5).
These capabilities would, at minimum, accelerate many areas of research while also creating serious vectors for misuse (Section 6). Regarding misuse, GPT2030's programming abilities, parallelization, and speed would make it a potent cyberoffensive threat. Additionally, its rapid parallel learning could be turned towards human behavior and thus used to manipulate and misinform with the benefit of thousands of "years" of practice.
On acceleration, a main bottleneck will be autonomy. In a domain like mathematics research where work can be checked automatically, I’d predict that GPT2030 will outcompete most professional mathematicians. In machine learning, I’d predict that GPT2030 will independently execute experiments and generates plots and write-ups, but that graduate students and research scientists will provide direction and evaluate results. In both cases, GPT2030 will be an integral part of the research process.
My forecast of GPT2030’s properties are not intuitive from looking at today’s systems, and they may be wrong, since there is significant uncertainty about how ML will look in 2030. However, properties (1.-5.) above are my median bet, and whatever GPT2030 is like, I doubt it will be “GPT-4 but a bit better”.
If I’m right, then whatever the impacts of AI are, they won’t be small. We should be preparing for those impacts now, asking what will happen at the largest scales (on the order of $1T, 10M lives, or significant disruptions to social processes). It’s better to be surprised now, rather than in 7 years when the system is already being rolled out.
1. Specific Capabilities
I expect GPT2030 to have superhuman coding, hacking, and mathematical abilities. I also expect it to be superhuman in its ability to read and process large corpora for patterns and insights and to recall facts. Finally, since AlphaFold and AlphaZero had superhuman abilities in protein structure prediction and game-playing, GPT2030 could as well, for instance if it was trained multimodally on similar data to the AlphaFold/AlphaZero models.
Programming. GPT-4 outperformed a strong human baseline on LeetCode problems posed after its training cutoff (Bubeck et al. 2023, Table 2), and passed the mock interview for several major tech companies (Figure 1.5). The velocity of improvement remains high, with a 19% jump from GPT-3 to 4. On the more challenging CodeForces competition, GPT-4 does less well, but AlphaCode is on par with the median CodeForces competitor. On the even more challenging APPS dataset, Parsel further outperforms AlphaCode (7.8%->25.5%). Looking forward, the forecasting platform Metaculus gives a median year of 2027 for 80% on APPS, which would exceed all but the very best humans.[4]
Hacking. I expect hacking to improve with general coding ability, plus ML models can scour large codebases for vulnerabilities much more scalably and conscientiously than humans. In fact, ChatGPT has already been used to help generate exploits.
Math. Minerva achieved 50% accuracy on a competition math benchmark (MATH), which is better than most human competitors. The velocity of progress is high (>30% in 1 year), and there is significant low-hanging fruit via autoformalization, reducing arithmetic errors, improving chain-of-thought, and better data[5]. Metaculus predicts 92% on MATH by 2025, and gives a median year of 2028 for AI winning a gold medal at the International Math Olympiad, on par with the best high school students in the world. I personally expect GPT2030 to be better than most professional mathematicians at proving well-posed theorems.[6]
Information processing. Factual recall and processing large corpora are natural consequences of language models’ memorization capabilities and large context windows. Empirically, GPT-4 achieves 86% accuracy on MMLU, a broad suite of standardized exams including the bar exam, MCAT, and college math, physics, biochemistry, and philosophy; even accounting for likely train-test contamination, this probably exceeds the breadth of knowledge of any living human. Regarding large corpora, Zhong et al. (2023) used GPT-3 to construct a system that discovered and described several previously unknown patterns in large text datasets, and scaling trends on a related task in Bills et al. (2023) suggest that models will soon be superhuman. Both of these works exploit the large context windows of LLMs, which are now over 100,000 tokens and growing.
More generally, ML models have a different skill profile than humans, since humans and ML were adapted to very different data sources (evolution vs. massive internet data). At the point that models are human-level at tasks such as video recognition, they will likely be superhuman at many other tasks (such as math, programming, and hacking). Furthermore, additional strong capabilities will likely emerge over time due to larger models and better data, and there is no strong reason to expect model capabilities to “level out” at or below human-level. While it is possible that current deep learning approaches will fall short of human-level capabilities in some domains, it is also possible that they will surpass them, perhaps significantly, especially in domains such as math that humans are not evolutionarily specialized for.
2. Inference Speed
(Thanks to Lev McKinney for running the performance benchmarks for this section.)
To study the speed of ML models, we’ll measure how quickly ML models generate text, benchmarking against the human thinking rate of 380 words per minute (Korba (2016), see also Appendix A). Using OpenAI's chat completions API, we estimate that gpt-3.5-turbo can generate 1200 words per minute (wpm), while gpt-4 generates 370 wpm, as of early April 2023. Smaller open source models like pythia-12b achieve at least 1350 wpm with out-of-the-box tools on an A100 GPU, and twice this appears possible with further optimization.
Thus, if we consider OpenAI models as of April, we are either at roughly 3x human speed, or equal to human speed. I predict that models will have faster inference speed in the future, as there are strong commercial and practical pressures towards speeding up inference. Indeed, in the week leading up to this post, GPT-4’s speed already increased to around 540wpm (12 tokens/second), according to Fabien Roger’s tracking data; this illustrates that there is continuing room and appetite for improvement.
My median forecast is that models will have 5x the words/minute of humans (range: [0.5x, 20x]), as that is roughly where there would be diminishing practical benefits to further increases, though there are considerations pointing to both higher or lower numbers. I provide a detailed list of these considerations in Appendix A, as well as comparisons of speeds across model scales and full details of the experiments above.
Importantly, the speed of an ML model is not fixed. Models’ serial inference speed can be increased by $k^2$ at a cost of a $k$-fold reduction in throughput (in other words, $k^3$ parallel copies of a model can be replaced with a single model that is $k^2$ times faster). This can be done via a parallel tiling scheme that theoretically works even for large values of $k^2$, likely at least 100 and possibly more. Thus, a model that is 5x human speed could be sped up to 125x human speed by setting $k=5$.
An important caveat is that speed is not necessarily matched by quality: as discussed in Section 1, GPT2030 will have a different skill profile than humans, failing at some tasks we find easy and mastering some tasks we find difficult. We should therefore not think of GPT2030 as a "sped-up human", but as a "sped-up worker" with a potentially counterintuitive skill profile.
Nevertheless, considering speed-ups is still informative, especially when they are large. For language models with a 125x speed-up, cognitive actions that take us a day could be completed in minutes, assuming they were within GPT2030's skill profile. Using the earlier example of hacking, exploits or attacks that are slow for us to generate could be created quickly by ML systems.
3. Throughput and Parallel Copies
Models can be copied arbitrarily subject to available compute and memory. This allows them to quickly do any work that can be effectively parallelized. In addition, once one model is fine-tuned to be particularly effective, the change could be immediately propagated to other instances. Models could also be distilled for specialized tasks and thus run faster and more cheaply.
There will likely be enough resources to run many copies of a model once it has been trained. This is because training a model requires running many parallel copies of it, and whatever organization trained the model will still have those resources at deployment time. We can therefore lower bound the number of copies by estimating training costs.
As an example of this logic, the cost of training GPT-3 was enough to run it for 9 x 1011 forward passes. To put that into human-equivalent terms, humans think at 380 words per minute (see Appendix A) and one word is 1.33 tokens on average, so 9 x 1011 forward passes corresponds to ~3400 years of work at human speed. Therefore, the organization could run 3400 parallel copies of the model for a full year at human working-speeds, or potentially the same number of copies for 2.4 months at 5x human speed. (Note: This latter point depends on how many parallel instances the organization can run, see footnote[7] for details.)
Let's next project this same “training overhang” (ratio of training to inference cost) for future models. It should be larger: the main reason is that training overhang is roughly proportional to dataset size, and datasets are increasing over time. This trend will be slowed as we run out of naturally-occuring language data, but new modalities as well as synthetic or self-generated data will still push it forward.[8] In Appendix B, I consider these factors in detail to project forward to 2030. I forecast that models in 2030 will be trained with enough resources to perform 1,800,000 years of work adjusted to human speed [range: 400k-10M].
Note that Cotra (2020) and Davidson (2023) estimate similar quantities and arrive at larger numbers than me; I'd guess the main difference is how I model the effect of running out of natural language data.
The projection above is somewhat conservative, since models may be run on more resources than they were trained on if the organization buys additional compute. A quick ballpark estimate suggests that GPT-4 was trained on about 0.01% of all computational resources in the world, although I expect future training runs to use up a larger share of total world compute and therefore have less room to scale up further after training. Still, an organization could possibly increase the number of copies they run by another order of magnitude if they had strong reasons to do so.
4. Knowledge Sharing
(Thanks to Geoff Hinton who first made this argument to me.)
Different copies of a model can share parameter updates. For instance, ChatGPT could be deployed to millions of users, learn something from each interaction, and then propagate gradient updates to a central server where they are averaged together and applied to all copies of the model. In this way, ChatGPT could observe more about human nature in an hour than humans do in a lifetime (1 million hours = 114 years). Parallel learning may be one of the most important advantages models have, as it means they can rapidly learn any missing skills.
The rate of parallel learning depends on how many copies of a model are running at once, how quickly they can acquire data, and whether the data can be efficiently utilized in parallel. On the last point, even extreme parallelization should not harm learning efficiency much, as batch sizes in the millions are routine in practice, and the gradient noise scale (McCandlish et al., 2018) predicts minimal degradation in learning performance below a certain “critical batch size”. We'll therefore focus on parallel copies and data acquisition.
I will provide two estimates that both suggest it would be feasible to have at least ~1 million copies of a model learning in parallel at human speed. This corresponds to 2500 human-equivalent years of learning per day, since 1 million days = 2500 years.
The first estimate uses the numbers from Section 3, which concluded that the cost of training a model is enough to simulate models for 1.8M years of work (adjusted to human speed). Assuming that the training run itself lasted for less than 1.2 years (Sevilla et al., 2022), this means the organization that trained the model has enough GPUs to run 1.5M copies at human speed.
The second estimate considers the market share of the organization deploying the model. For example, if there are 1 million users querying the model at a time, then the organization necessarily has the resources to serve 1 million copies of the model. As a ballpark, ChatGPT had 100 million users as of May 2023 (not all active at once), and 13 million active users/day as of January 2023. I’d assume the typical user is requesting a few minutes worth of model-generated text, so the January number probably only implies around 0.05 million person-days of text each day. However, it seems fairly plausible that future ChatGPT-style models would 20x this, reaching 250 million active users/day or more and hence 1 million person-days of data each day. As a point of comparison, Facebook has 2 billion daily active users.
5. Modalities, Tools, and Actuators
Historically, GPT-style models have primarily been trained on text and code, and had limited capacity to interact with the outside world except via chat dialog. However, this is rapidly changing, as models are being trained on additional modalities such as images, are being trained to use tools, and are starting to interface with physical actuators. Moreover, models will not be restricted to anthropocentric modalities such as text, natural images, video, and speech---they will likely also be trained on unfamiliar modalities such as network traffic, astronomical images, or other massive data sources.
Tools. Recently-released models use external tools, as seen with ChatGPT plugins as well as Schick et al. (2023), Yao et al. (2022), and Gao et al. (2022). Text combined with tool use is sufficient to write code that gets executed, convince humans to take actions on their behalf, make API calls, make transactions, and potentially execute cyberattacks. Tool use is economically useful, so there will be strong incentives to further develop this capability.
ChatGPT is reactive: user says X, ChatGPT responds with Y. Risks exist but are bounded. Soon it will be tempting to have proactive systems - an assistant that will answer emails for you, take actions on your behalf, etc. Risks will then be much higher.
— Percy Liang (@percyliang) February 27, 2023
New modalities. There are now large open-source vision-language models such as OpenFlamingo, and on the commercial side, GPT-4 and Flamingo were both trained on vision and text data. Researchers are also experimenting with more exotic pairs of modalities such as proteins and language (Guo et al., 2023).
We should expect the modalities of large pretrained models to continue to expand, for two reasons. First, economically, it is useful to pair language with less familiar modalities (such as proteins) so that users can benefit from explanations and efficiently make edits. This predicts multimodal training with proteins, biomedical data, CAD models, and any other modality associated with a major economic sector.
Second, we are starting to run out of language data, so model developers will search for new types of data to continue benefiting from scale. Aside from the traditional text and videos, some of the largest existing sources of data are astronomical data (will soon be at exabytes per day) and genomic data (around 0.1 exabytes/day). It is plausible that these and other massive data sources will be leveraged for training GPT2030.
The use of exotic modalities means that GPT2030 might have unintuitive capabilities. It might understand stars and genes much better than we do, even while it struggles with basic physical tasks. This could lead to surprises, such as designing novel proteins, that we would not have expected based on GPT2030’s level of “general” intelligence. When thinking about the impacts of GPT2030, it will be important to consider specific superhuman capabilities it might possess due to these exotic data sources.
Actuators. Models are also beginning to use physical actuators: ChatGPT has already been used for robot control and OpenAI is investing in a humanoid robotics company. However, it is much more expensive to collect data in physical domains than digital domains, and humans are also more evolutionarily adapted to physical domains (so the bar for ML models to compete with us is higher). Compared to digital tools, I’d therefore expect mastery of physical actuators to occur more slowly, and I’m unsure if we should expect it by 2030. Quantitatively, I’d assign 40% probability to there being a general-purpose model in 2030 that is able to autonomously assemble a scale-replica Ferrari as defined in this Metaculus question.
6. Implications of GPT-2030
We’ll next analyze what a system like GPT2030 would mean for society. A system with GPT2030’s characteristics would, at minimum, significantly accelerate some areas of research, while also possessing powerful capacities for misuse.
I’ll start by framing some general strengths and limitations of GPT2030, then use this as a lens to analyze both acceleration and misuse.
Strengths. GPT2030 represents a large, highly adaptable, high-throughput workforce. Recall that GPT2030 could do 1.8 million years of work[9] across parallel copies, where each copy is run at 5x human speed. This means we could (subject to parallelism constraints) simulate 1.8 million agents working for a year each in 2.4 months. As discussed above, we could pay 5x per FLOP to get an additional 25x speedup (to 125x human speed), so we could also simulate 14,000 agents working for a year each in 3 days[10].
Limitations. There are three obstacles to utilizing this digital workforce: skill profile, experiment cost, and autonomy. On the first, GPT2030 will have a different skill profile from humans that makes it worse at some tasks (but better at others). On the second, simulated workers still need to interface with the world to collect data, which has its own time and compute costs. Finally, on autonomy, models today can only generate a few thousand tokens in a chain-of-thought before getting “stuck”, entering a state where they no longer produce high-quality output. We’d need significant increases in reliability before delegating complex tasks to models. I expect reliability to increase, but not without limit: my (very rough) guess is that GPT2030 will be able to run for several human-equivalent days before having to be reset or steered by external feedback. If models run at a 5x speed-up, that means they need human oversight every several hours.
Therefore, the tasks that GPT2030 would most impact are tasks that:
- Leverage skills that GPT2030 is strong at relative to humans.
- Only require external empirical data that can be readily and quickly collected (as opposed to costly physical experiments).
- Can be a priori decomposed into subtasks that can be performed reliably, or that have clear and automatable feedback metrics to help steer the model.
Acceleration. One task that readily meets all three criteria is mathematics research. On the first, GPT2030 will likely have superhuman mathematical capabilities (Section 1). On the second and third, math can be done purely by thinking and writing, and we know when a theorem has been proved. There are furthermore not that many mathematicians in total in the world (e.g. only 3,000 in the US) so GPT2030 could likely simulate more than the annual output of all mathematicians every several days.
Significant parts of ML research also meet the criteria above. GPT2030 would be superhuman at programming, which includes implementing and running experiments. I’d guess it will also be good at presenting and explaining the results of experiments, given that GPT-4 is good at explaining complex topics in an accessible way (and there is significant market demand for this). Therefore, ML research might reduce to thinking up good experiments to run and interfacing with high-quality (but potentially unreliable) write-ups of the results. In 2030, grad students might therefore have the same resources as a professor with several strong students would have today.
Parts of social science could also be significantly accelerated. There are many papers where the majority of the work is chasing down, categorizing, and labeling scientifically interesting sources of data and extracting important patterns—see Acemoglu et al. (2001) or Webb (2020) for representative examples. This satisfies requirement (3.) because categorization and labeling can be decomposed into simple subtasks, and it satisfies requirement (2.) as long as the data is available on the internet, or could be collected through an online survey.
Misuse. Beyond acceleration, there would be serious risks of misuse. The most direct case is cyberoffensive hacking capabilities. Inspecting a specific target for a specific style of vulnerability could likely be done reliably, and it is easy to check if an exploit succeeds (subject to being able to interact with the code), so requirement (3.) is doubly satisfied. On (2.), GPT2030 would need to interact with target systems to know if the exploit works, which imposes some cost, but not enough to be a significant bottleneck. Moreover, the model could locally design and test exploits on open source code as a source of training data, so it could become very good at hacking before needing to interact with any external systems. Thus, GPT2030 could rapidly execute sophisticated cyberattacks against large numbers of targets in parallel.
A second source of misuse is manipulation. If GPT2030 interacts with millions of users at once, then it gains more experience about human interaction in an hour than a human does in their lifetime (1 million hours = 114 years). If it used these interactions to learn about manipulation, then it could obtain manipulation skills that are far greater than humans—as an analogy, con artists are good at tricking victims because they’ve practiced on hundreds of people before, and GPT2030 could scale this up by several orders of magnitude. It could therefore be very good at manipulating users in one-on-one conversation, or at writing news articles to sway public opinion.
Thus in summary, GPT2030 could automate almost all mathematics research as well as important parts of other research areas, and it could be a powerful vector of misuse regarding both cyberattacks and persuasion/manipulation. Much of its impact would be limited by “oversight bottlenecks”, so if it could run autonomously for long periods of time then its impact may be larger still.
Thanks to Louise Verkin for transcribing this post to Ghost format, and Lev McKinney for running empirical benchmark experiments. Thanks to Karena Cai, Michael Webb, Leo Aschenbrenner, Anca Dragan, Roger Grosse, Lev McKinney, Ruiqi Zhong, Sam Bowman, Tatsunori Hashimoto, Percy Liang, Tom Davidson, and others for providing feedback on drafts of this post.
Appendix: Runtime and Training Estimates for Future Models
A. Words per minute
First we’ll estimate the word per minute of humans and of current models. Then we’ll extrapolate from current models to future models.
For humans, there are five numbers we could measure: talking speed, reading speed, listening speed, and both “elliptic” and “extended” thinking speed. Regarding the first three, Rayner and Clifton (2009) say that reading speed is 300 words per minute[11] and speaking is 160 words per minute[12], and that listening can be done 2-3 times faster than speaking (so ~400 words per minute)[13]. For thinking speed, we need to distinguish between “elliptic” and “extended” thought—it turns out that we think in flashes of words rather than complete sentences, and if we extend these flashes to full sentences we get very different word counts (~10x different). Korba (2016) find that elliptic thought is 380 words per minute while extended thought is ~4200 words per minute. Since most of these numbers cluster in the 300-400 wpm range, I’ll use 380 words per minute as my estimate of human thinking speed. Using the 4:3 token to word ratio suggested by OpenAI, this comes out to 500 tokens per minute.[14]
(Thanks to Lev McKinney for running the evaluations in the following paragraphs.)
Next, let’s consider current models. We queried gpt-3.5-turbo and gpt-4, as well as several open source models from EleutherAI, to benchmark their inference speed. We did this by querying the models to count from 1 to n, where n ranged from 100 to 1900 inclusive in increments of 100. Since numbers contain more than one token, we cut the model off when it reached n tokens generated, and measured the time elapsed. We then ran a linear regression with a bias term to account for latency in order to estimate the asymptotic number of tokens per second.
GPT-4 and GPT-3.5-turbo were queried from the OpenAI AIP in early April 2023. All experiments for the pythia models were performed using deepspeed's injected kernels and fp16 models on a single A100 GPU.[15] Code for replicating these results can be found at https://github.com/levmckinney/llm-racing.
The raw data is plotted in Figure 1 below, while Figure 2 and Table 1 give the resulting estimated tokens per minute.
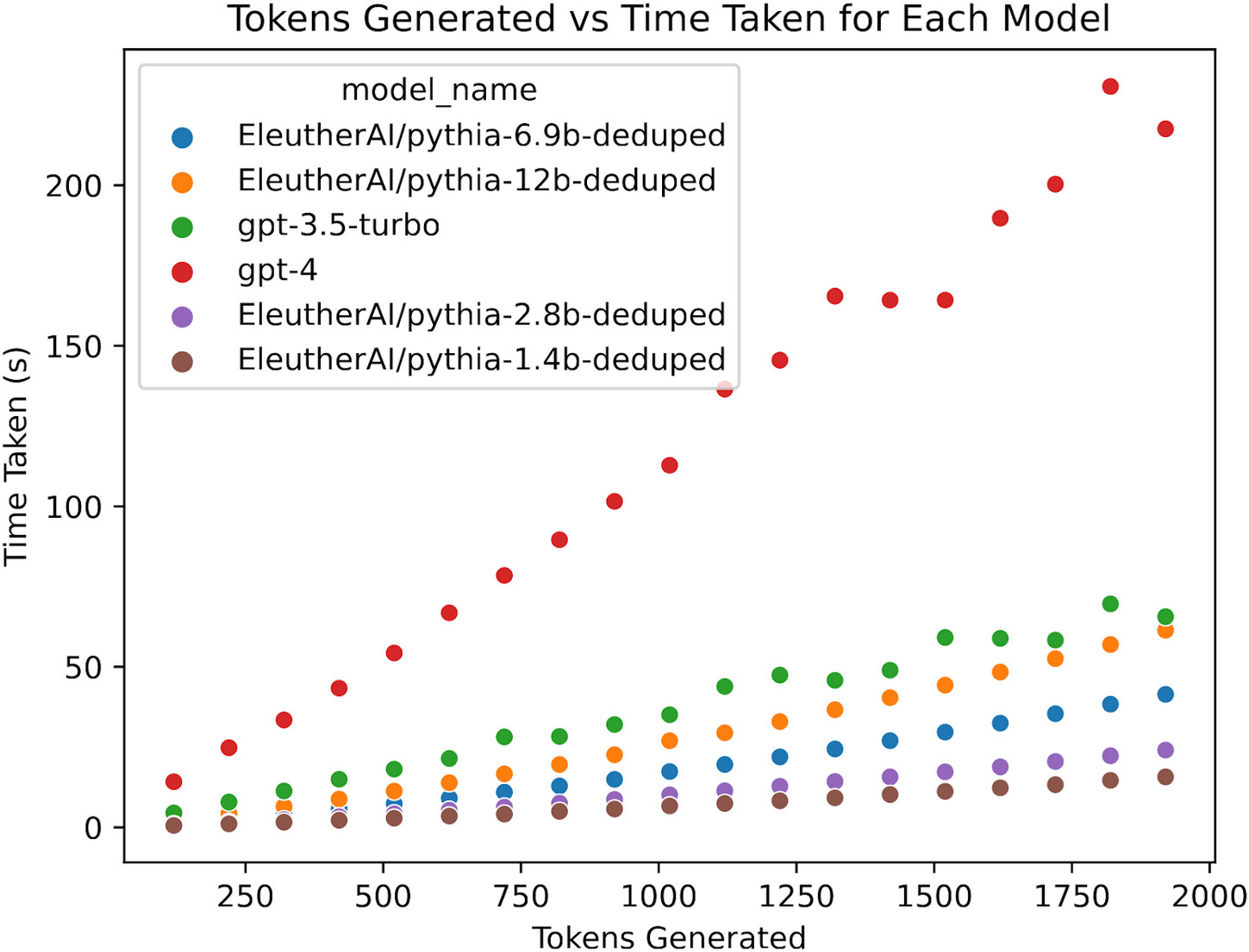
Figure 1 demonstrates how model inference scales with token input. Note that time per token remains relatively linear at these context lengths.
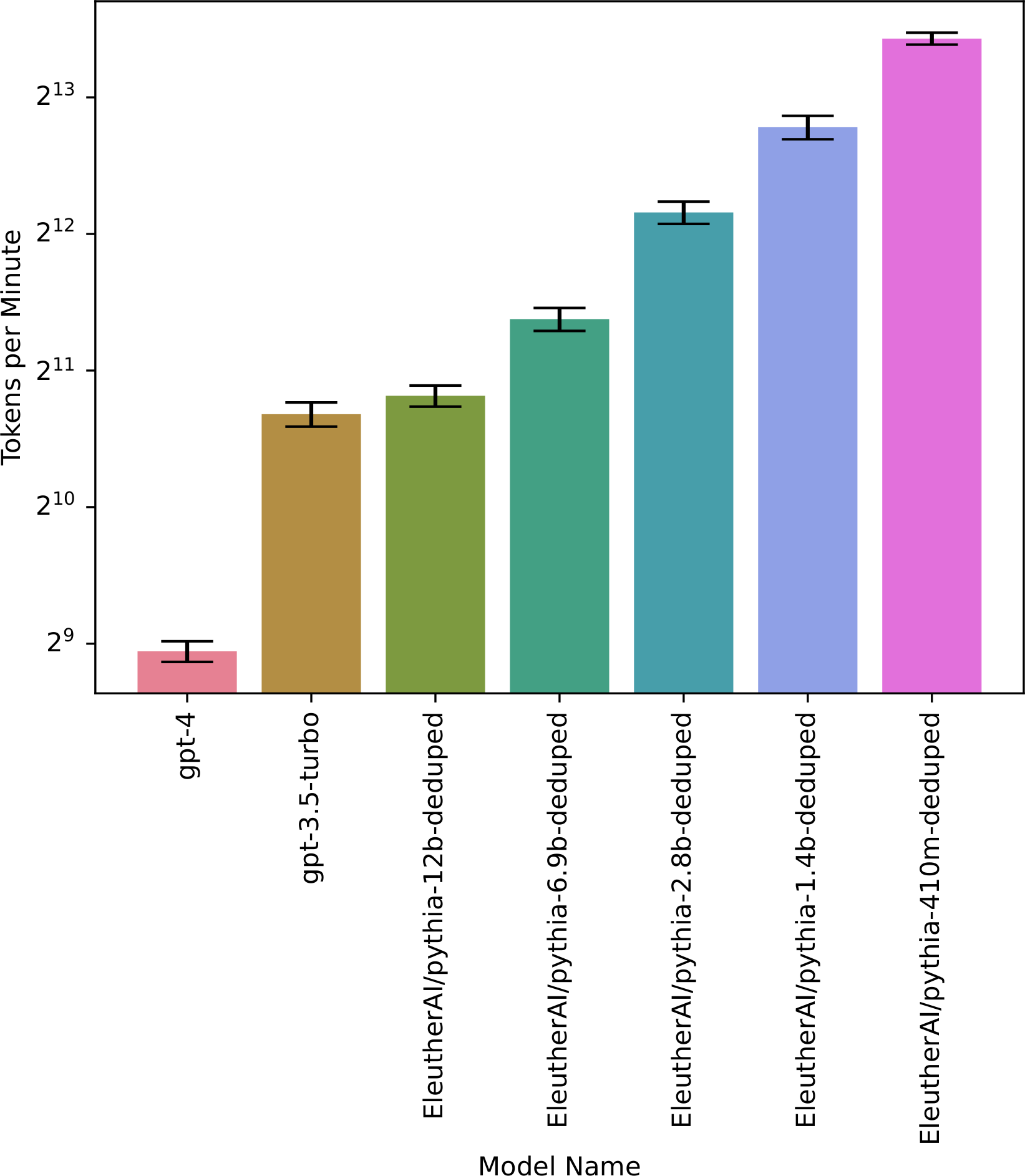
Figure 2 and the table below demonstrates how model inference speed scales with size. Error bars are 95% confidence intervals.
| Model name | Tokens per minute |
|---|---|
| gpt-4 | 493 |
| gpt-3.5-turbo | 1641 |
| EleutherAI/pythia-12b-deduped | 1801 |
| EleutherAI/pythia-6.9b-deduped | 2659 |
| EleutherAI/pythia-2.8b-deduped | 4568 |
| EleutherAI/pythia-1.4b-deduped | 7040 |
| EleutherAI/pythia-410m-deduped | 11039 |
| EleutherAI/pythia-160m-deduped | 21580 |
| EleutherAI/pythia-70m-deduped | 31809 |
Thus, GPT-4 is close to the human benchmark of 500 tokens/minute, while GPT-3.5-turbo is about 3x faster. Smaller models are an order of magnitude faster still, which indicates that even faster inference is possible, although it also suggests that future larger models may be slower (not accounting for better hardware and other optimizations). Inference speed in practice seems to slow down sublinearly with model size–in the pythia models, increasing size by a factor of k decreases inference speed by approximately k0.6.
How will models’ words per minute change in the future? There are factors pushing towards both faster and slower speeds:
- Larger models are more expensive to run, especially if they have more layers (larger widths can be parallelized, but larger depths cannot be).
- Inference will generally be optimized more, e.g. via early exiting, sparse attention, cross-GPU parallelization, or better hardware. There is quite a bit of headroom here, especially from parallelization and hardware (see discussion below).
- In particular, there will be quite a bit of incentive to make models fast enough to be easily usable (e.g. faster than human reading speed).
- After staring at lots of data about trends in model size, GPU architecture, etc. for 10+ hours, I mostly concluded that I am very uncertain about how the competing trends of larger models vs. better hardware and software will play out. My median guess would be that we get models that are noticeably faster than humans (5x), but I wouldn’t be surprised by anything from 2x slower to 20x faster.
- Importantly, these speeds are only if we demand maximum throughput from the GPUs. If we are willing to sacrifice throughput by a factor of k, we can speed up inference by a factor of k^2, up to fairly large values of k. So if models are only 5x faster than humans by default, they could instead be 125x faster in exchange for a 5x reduction in throughput, and this could be pushed further still if necessary.
Finally, aside from raw speed, words/minute isn’t apples-to-apples across humans and language models. For one, the language models aren’t just thinking but also writing, and in some cases they are writing content that would be much slower for humans to produce (e.g. code, or arguments with references). In the other direction, language models are currently quite verbose, so one word from a language model does less “work” than one word from a human. This verbosity could be fine-tuned away, but it’s not clear we could match the efficiency of elliptic thought in humans. Finally, tokenization and word complexity will change over time, and so the 1.333x conversation ratio from words to tokens won’t stay constant (indeed, I’d guess it’s already an underestimate for today’s models since they now tend to use complex words with prefixes and suffixes).
Details on parallelization and hardware speed-ups. As described in How Fast Can We Perform a Forward Pass?, there are parallel tiling schemes that significantly increase serial inference speed with only minor overhead. For instance, parallel tiling of GPT-3 would increase its inference speed by 30x or more on an A100 cluster relative to running it on a single 8-GPU machine[16]. These optimizations are not currently widely used because they aren’t useful for training and slightly decrease inference throughput, but people would start using them once inference time becomes a bottleneck.
For hardware, GPUs are becoming more powerful, which will speed up inference. However, GPUs are also being built to require larger arithmetic intensity, which will decrease the amount of parallel tiling (see previous point) that is possible. For reference, I’ve included the specs of all NVIDIA GPUs below. The “Mem Bandwidth” column measures the serial throughput without any cross-GPU parallelization[17], while the final M3/C2 column measures serial throughput with the maximum cross-GPU parallelization that maintains high enough arithmetic intensity[18]. The former is steadily increasing, while the latter jumps around but has tended to decrease.
| Date | GPU | Compute | Memory | Clock Speed | Mem Bandwidth | Interconnect | Network | M^3 / C^2 |
|---|---|---|---|---|---|---|---|---|
| 05/2016 | P100 | ~84TF | 16GB | 1.45GHz | 720GB/s | 160GB/s | 53M | |
| 12/2017 | V100 16GB | 125TF | 16GB | 1.49GHz | 900GB/s | 300GB/s | ~25GB/s | 47M |
| 03/2018 | V100 32GB | 125TF | 32GB | 1.49GHz | 900GB/s | 300GB/s | ~100GB/s | 47M |
| 05/2020 | A100 40GB | 312 TF | 40GB | 1.38GHz | 1555GB/s | 600GB/s | ~400GB/s | 39M |
| 11/2020 | A100 80GB | 312 TF | 80GB | 1.38GHz | 2039GB/s | 600GB/s | ~400GB/s | 87M |
| ~8/2022 | H100 | 2000 TF | 80GB | 1.74GHz | 3072GB/s | 900GB/s | 900GB/s? | 7.2M |
B. Training overhang
There will likely be enough resources to run many copies of a model once it has been trained. GPT-3 took 3.1e23 FLOPs to train and requires 3.5e11 FLOPs for a forward pass, so 9e11 forward passes could be run for the cost of training. Using the 500 tokens per minute conversion from Appendix A, this would correspond to ~3400 human-years of thinking.
How will this change in the future? I’ll use the Chinchilla scaling law and projections of future training costs to form an initial estimate, then I’ll consider ways we could deviate from the Chinchilla trend. For future training costs, I consider the projection in Besiroglu et al. (2022), who analyzed over 500 existing models to extrapolate compute trends in machine learning. Their central projection of training FLOPs in 2030 is 4.7e28, with a range of 5.1e26 to 3.0e30. Metaculus has a similar estimate of 2.3e27 (for Jan 1, 2031)[19]. Taking the geometric median, I’ll use 1.0e28 as my estimate of training FLOPs, or a 33,000-fold increase over GPT-3. Since the Chinchilla scaling law implies that model size (and hence inference cost) scales as the square-root of training cost, this means the training overhang should increase by sqrt(33000), or around 180-fold. The 3400 human-years of thinking would thus increase to 620,000 human-years. However, there’s an additional consideration, which is that GPT-3 was actually trained with suboptimal scaling. The ideal size of GPT-3 (given its training cost) would have been 4 times smaller, so we need to add an additional factor of 4, to get 2.5M human-years, with a range from 0.8M to 9M accounting for uncertainty in the number of training FLOPs[20].
Next, let’s consider deviations from the Chinchilla scaling law. The most obvious deviation is that we might soon run out of data. This could either mean that larger models becomes more attractive relative to more data (which would decrease training overhang), or that we generate additional synthetic data (makes creating data more computationally-expensive, which would increase training overhang), or we move to new data-rich modalities such as video (unclear effect on training overhand, probably increases it). To roughly bound these effects:
- Lower bound: Villalobos et al. (2022) estimate that we will run out of high-quality language data (e.g. Wikipedia, books, scientific papers, etc.) by 2026, although we will not run out of low-quality data (e.g. web pages) before 2030. In a pessimistic world where high-quality data is a completely binding constraint, the model in Villalobos et al. implies an 8x increase in dataset size by 2030, meaning the training overhang would increase only 8-fold instead of 180-fold.
- Upper bound: If we run out of data, we might generate new data synthetically. One possibility for this is chain-of-thought distillation as in Huang et al. (2022). In that paper, 32 chains of thought are generated on each input instance, only some of which are used for training updates. Assume that on average 5 of the 32 chains of thought get used for training updates, and that a backward pass is twice the cost of a forward pass. Then the cost per training update is equivalent to 2 + 32/5 = 8.4 forward passes, compared to 3 previously, or a 2.8x increase. Under Chinchilla scaling this cost propagates forward to an additional sqrt(2.8) = 1.7x increase in training overhang, i.e. 300-fold instead of 180-fold.
Overall, the lower bound seems fairly pessimistic to me as we’ll almost certainly find some way to leverage lower-quality or synthetic data. On the other hand, beyond running out of data, we might find ways to make the training process more efficient via e.g. curriculum learning. Accounting for this, my personal guess is we will end up somewhere between a 12-fold and 200-fold increase in overhang, with a central estimate of 100x, yielding a training overhang of around 1.8M human-years of thinking. We would also want to expand our range to account for the additional uncertainty from deviations to the Chinchilla scaling law. Subjectively, I’d increase the range to be 0.4M to 10M.
All of these estimates are for 2030. In general, the numbers above would be larger for later years and smaller for earlier years.
As an additional point of comparison, Karnofsky (2022) (following Cotra, 2020) estimates that the cost to train a human-level model would be enough compute to run 100 million copies of the model for a year each, although that estimate assumes training runs that use 1e30 FLOPs instead of 1e28. Even accounting for that, this seems a bit high to me, and I’d have been closer to 18 million than 100 million based on the square-root scaling above.
Though actually, zeroth order forecasting already helps a lot if done right! Many who were surprised by ChatGPT would have already been impressed by text-davinci-003, which was released much earlier but with a less user-friendly interface. ↩︎
As a specific point of comparison, GPT-3 only had enough compute to run 3400 human-adjusted years of work, and I'd guess it could do less than 100 human-adjusted years of learning per day. I'd guess GPT-4 is at 130,000 human-adjusted years of work and 125 adjusted years of learning. So GPT2030 is at least an order of magnitude larger on both axes. ↩︎
Throughout, the range in brackets represents the 25th to 75th percentile of my predictive distribution. In practice the range is probably too narrow because I only did a mainline forecast without accounting for “other” options. ↩︎
Qualitatively, GPT-4 Bubeck et al. also found that GPT-4 could produce a 400-line 3D game zero-shot, which is probably impossible for nearly all humans. ↩︎
See Forecasting ML Benchmarks in 2023 for some further discussion of this. ↩︎
Concretely, I’d assign 50% probability to the following: “If we take 5 randomly selected theorem statements from the Electronic Journal of Combinatorics and give them to the math faculty at UCSD, GPT2030 would solve a larger fraction of problems than the median faculty and have a shorter-than-median solve time on the ones that it does solve.” ↩︎
I am assuming the initial training run was less than a year (Sevilla et al., 2022), from which it follows that the organization can at least parallelize enough to run the 9 x 1011 forward passes within a year, subject to constraints on inference speed. To do so in 2.4 months, they may need further improvements. I think this is plausible (but not certain), both because the organization might have trained the model in less than a year, and because there may be tricks available for inference that were not for training. ↩︎
A second factor is that GPT-3 was trained suboptimally, and with optimal (Chinchilla-style) scaling the training overhang would be 4x larger already. ↩︎
Adjusted to human working speeds. ↩︎
The math here is that with a perfect speed-up, 1.8 milion / 25 = 72,000, but the extra 5x per FLOP makes it 14,000. ↩︎
“skilled readers typically reading at rates between 250-350 words per minute” ↩︎
“estimates of normal speaking rate range from 120 to 200 words per minute” ↩︎
“Experiments on compressed speech suggest that comprehension can be successful at two times or more the normal rate (e.g., Dupoux & Green, 1997)” ↩︎
I personally think that 4:3 is too optimistic and 3:2 or even 2:1 might be more realistic, but I’ll stick to 4:3 throughout the doc since it was the main citation I found. ↩︎
The performance for pythia models can likely be improved further. For instance, NVIDIA has reported about 80 tokens per second on a comparable model to pythia-6.9 billion on a single A100. When allowing for more hardware, they have even shown approximately 90 tokens per second using 8 way tensor parallelism on an 8xA100 SuperPod architecture when generating using a 20B parameter GPT model. ↩︎
A single A100 can handle matrix multiplies as small as 1024x1024 before becoming bottlenecked on memory reads, and the main operation in GPT-3 is a 12288 x (4*12288) matrix multiply, meaning we would tile it across 576 GPUs (72 machines). This would naively mean a 72x speedup, but there is probably enough overhead that I’m estimating closer to 30x. ↩︎
Roughly speaking, with no cross-GPU tiling, the serial speed of inference is determined by the memory bandwidth, e.g. the A100 with 2039GB/s bandwidth should be able to complete 2039/175 \approx 12 forward passes with a 175B parameter model per second (up to constant factors). ↩︎
With parallel tiling, the forward passes per second is proportional to M3/54C2L, where C = Compute, M = Mem bandwidth, and L = # of layers. (see here for details). The final column gives M3/C2. ↩︎
Metaculus also estimates that the largest model trained will have 2.5e15 parameters (for Jan 1, 2030), meaning a forward pass costs 5e15 FLOPs. If we naively take the ratio, we again get 9e11 forward passes, but I think this is not the right calculation, because the largest model trained will likely not be state-of-the-art but rather something like the 174 trillion parameter BaGuaLu model. ↩︎
I’m basing this on Metaculus giving a range of 5M to 660M as the interquartile range of their estimate, and propagating the uncertainty through the square-root function. ↩︎
